I've recently implemented the ability to monitor services from multiple locations in Vigilant. Vigilant is a open source and self hostable monitoring application that is made to monitor websites specifically. But the uptime monitoring works on any service.
Up until now the implementation of the uptime / latency monitor was simple, the main application sends a request to the service and stores the result. This means that when the main application has a slight network hiccup it will see the application as unavailable and send a notification. This is a false positive! Not what we want because when you check what's wrong, you notice that nothing is wrong! These false positives are not acceptable and have to be prevented. How? By checking from multiple locations across the globe.
Requirements
I had a few requirements for this as I want to be able to purchase a cheap VPS via sites like lowendbox or lowendtalk and deploy quickly to these machines with minimal configuration. This allows me to setup multiple monitoring locations with a small budget. The ideal workflow would be to ssh into the machine, setup a docker compose file with an .env file and run it. The environment file would contain the URL to Vigilant. This requires the remote uptime containers to register themselves with the main application and this must be done in a secure way. Because Vigilant is open source and self hostable, I must also take into consideration the ease of setup for people who self-host Vigilant.
To summarize, the requirements for remote uptime monitoring in Vigilant are:
Able to run on random remote servers
Quick to setup using Docker
Automatic registering with Vigilant
Secure
Easy to use and understand for self-hosters
The Approach
My initial idea was to leverage the main application's queue worker by deploying a queue worker remotely and setting up a secure connection between them using something like Wireguard. Vigilant is written in PHP using the Laravel framework, for queuing it uses Laravel Horizon. This is a queuing system built on top of Redis. All monitoring tasks in Vigilant are executed on this queue, it allows for multiple queues to exist identified by an unique name. Vigilant has queues for uptime, dns, lighthouse etc, this way the different monitors don't block each other and resources can be managed per type of monitor.
To start a queue worker we can run a single command in a container, exactly like the `horizon` container does now in the current Docker compose setup.
So my first try was to deploy a remote Horizon worker that just handles one queue and name it something like uptime:de or uptime:us to specify the location. Horizon already runs in a separate Docker container.
I quickly realized that this will not work well, Horizon requires Redis and does not support multiple Redis servers. Redis is single threaded meaning only one operation at a time. With a VPN across the world the latency from the worker would block Redis for too long affecting the entire application.
So what about a proxy? Setup a socks5 proxy and run the checks via that? Well, first of all they aren't auto-registering and Vigilant also requires latency information from the endpoint to the service which is not possible when using a proxy like this. We will have to write our own proxy to get the exact data we need.
I've done something similar for the Lighthouse checks, they run in a separate Docker container using a Go application. This app provides a HTTP server which Vigilant calls with the URL to run Lighthouse on. When it is done it will send the result back to Vigilant. Something similar for uptime would be good, send the request to this Go application but then directly return the response.
Why Go and not PHP? Vigilant is written in PHP so the obvious choice to write these external applications in would also be PHP, right? While PHP is great is does not for example have an inbuilt web server that supports multiple connections, the ability to schedule things on it's own or to run things on startup. Other languages like Go and Python do which is why I choose not to write this in PHP. If written in PHP it would need a separate web server and a mechanism to detect when the container starts and stops to run a specific piece of code.
Building the outpost
I've decided to call these containers 'outposts' as they are remotely located from the main application.
These are the things that the outpost needs to do:
Self-registration
When the container starts, it immediately registers itself with Vigilant without requiring additional configuration.Self-unregistration
Before shutting down (or when the container is stopped), the outpost sends a unregistration signal to remove itself from the active outpost list. This prevents stale entries or “ghost” outposts.HTTP server for uptime checks
The outpost exposes a small HTTP API that Vigilant can call to perform checks.Check execution
It supports both HTTP and Ping checks, measuring round-trip latency and returning the raw timing data back to Vigilant.
I've implemented these things into the Go application, once it starts up it will find it's own public IP address and select a random port to listen to. It will then send those details to Vigilant and starts a HTTP server.
Via a Github action it is built into a Docker image and hosted on the Github container registry. The resulting docker compose file looks like this and is all that is required to setup an outpost:
services:
outpost:
image: ghcr.io/govigilant/vigilant-uptime-outpost:latest
restart: always
network_mode: host
environment:
- VIGILANT_URL=https://<Vigilant instance URL here>
- OUTPOST_SECRET=<random secret string here>You can view the source for the outpost here: https://github.com/govigilant/vigilant-uptime-outpost
Running uptime checks via outposts
Vigilant tracks which outposts are available and every time an uptime check it due it will select an outpost to run the check on. When an outpost registers itself, Vigilant will determine the lat/long and country code of the outpost.
The lat/long is then also determined for the monitored service to find the closest outpost. This is then used to ensure that most of the uptime checks are done from the closest outpost.
When a request to an outpost fails it will try another and mark that outpost as unavailable to prevent another process from using it. Then a background task periodically checks the unavailable outposts, removes them if they are unreachable or marks them as available when they work.
This also allows us to check from multiple locations when a service is down with a small tradeoff that the detection takes a bit longer due to the additional checks. When an outpost responds with the message that a service is down it will check two additional outposts to ensure this is really the case. The small time tradeoff is worth it here to reduce the amount of false positives.
For those who are interested, here is the source code for an uptime check.
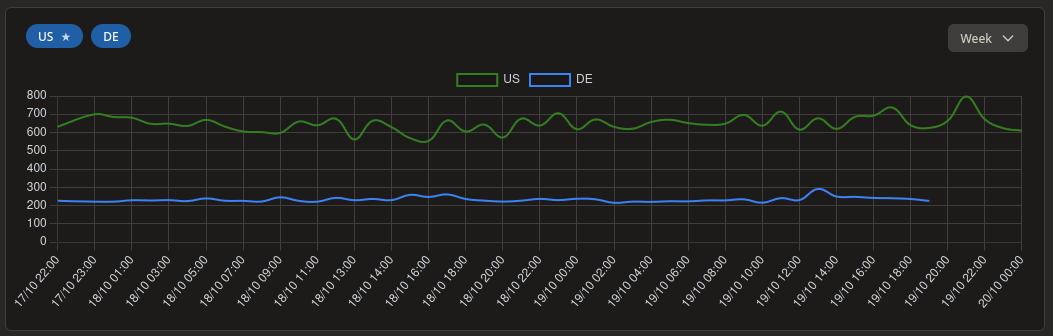
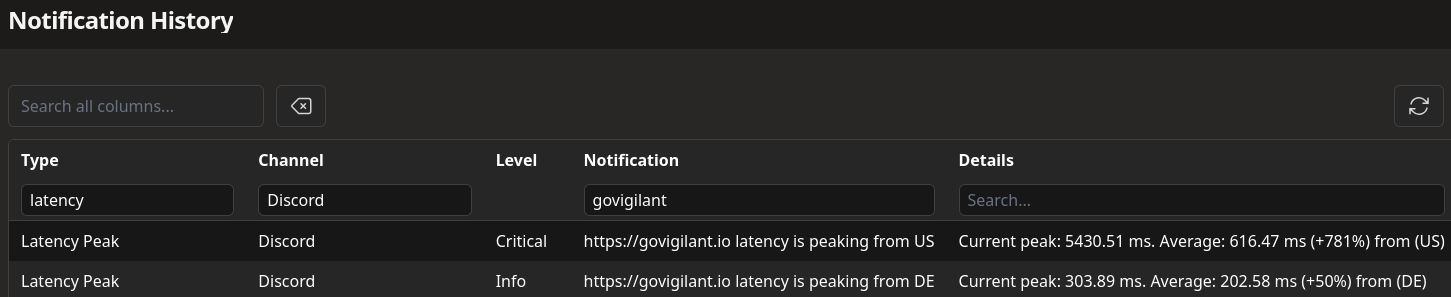
Now that we also have a country per result we can incorporate that into the dashboard and notifications. When latency increases from a specific country Vigilant will now add that to the notification.
Securing the outposts
For security there are two concerns, how to prevent anyone from registering an outpost and how to ensure the communication from and to the outposts are encrypted.
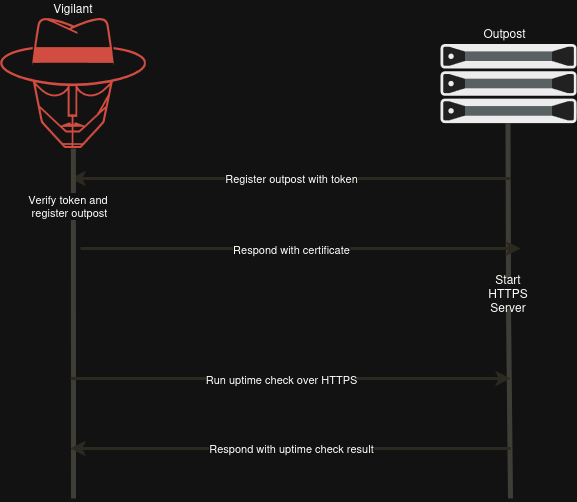
Vigilant itself runs on HTTPS, at least it should (I can't speak for self-hosted instances). But we consider the initial request from the outpost to Vigilant as secure because it goes over HTTPS with the secret token. To ensure we can trust the outpost, Vigilant and the outpost both have an API token. Vigilant sends the same key when running uptime checks, without this token you are unable to register an outpost or run an uptime check.
But the outposts start their own webserver on a random port and don't have a certificate which causes the traffic to go via HTTP, not good. We need a way to run the outposts webserver on HTTPS. Should we setup DNS and use a reverse proxy to handle this? While that would be possible it goes against our minimal configuration principle. A self signed certificate then? Yes possible, but our main application wouldn't be able to verify the certificate.
The first thing an outpost does is register itself, what if it gets a certificate from Vigilant? Vigilant can return a signed certificate which the outpost can use. Only Vigilant needs to be able to verify the certificate. This is exactly how I've implemented it, Vigilant acts as the root CA and generates 30 day valid certificates for an outpost. The outpost then starts a HTTPS server which causes the communication from Vigilant to the outposts to be encrypted.
The single point of failure
Outposts make it possible to monitor from multiple geographical regions but all requests are initiated from Vigilant, if Vigilant the application or the network it runs on becomes unavailable then no more checks are ran. This is not something that I want to get into now but I do monitor my monitoring service using Uptime Kuma.
But in order to solve this, Vigilant needs to run on multiple machines at the same time which is another layer of complexity where this project isn't big enough for currently. Vigilant runs in Docker so something like Docker Swarm would be possible.
Multi-Location Monitoring for Self Hosters
When you host your own applications, for fun, privacy or to save costs it takes some effort to setup monitoring from different locations. Most self hostable monitoring tools only support a single location, you could place a monitoring application like the popular open source option Uptime Kuma on multiple servers but then you run into situations like location A is saying your service is down while location B says it's up. Ideally you'd have one application which checks this but it really depends on your use case. For a homelab it is overkill but for a business it's essential, I'm personally still running Uptime Kuma in my homelab but my other sites are monitored with Vigilant.
So to start monitoring from multiple location with Vigilant you can follow the multi location uptime monitoring guide in the documentation.
Vigilant now makes it possible to self host uptime monitoring from multiple locations but it requires managing multiple servers. As I'm attempting to make Vigilant self sustainable I also offer a hosted version for which I am setting up this infrastructure. I'm toying with the idea to make this accessible for self hosters by letting them connect to Vigilant's hosted outpost for a small yearly price. That way you remain in control of your own data but do not have to worry about the worldwide infrastructure. I'd love to get feedback on this idea and/or hear if anyone is interested in this, please send me an email on [email protected] and let's chat!
Conclusion
Adding outposts to Vigilant not only solves the false positive issue but also opens the door to a more scalable and resilient architecture. With outposts, monitoring is no longer tied to a single server but it becomes distributed. The self-registering design keeps the setup experience simple for self-hosters (and for me hosting govigilant), while the secure certificate exchange ensures that communication remains trusted without requiring much configuration or DNS management.
Vigilant can now confidently say it doesn’t just monitor uptime; it verifies it from around the world.